
Key Takeaways :
- Removing sensitive data from model inputs does not make your model fair
- There are numerous definitions of fairness, making it possible to measure and decrease bias in a variety of ways
- We can assess the fairness of data, and models, and take fairness measures at various stages of the machine-learning pipeline
- In the biased world we live in, mitigating biases and fairness in AI has an impact on model accuracy, hence we need to check a trade-off between accuracy and fairness
The rapid advancement of machine learning has brought the concept of biases and fairness in AI to the forefront of discussions. This surge in interest has been driven by chatter about the potential harm that biased AI systems could inflict. Discriminatory biases within machine learning models can perpetuate existing inequalities, reinforce biases, and harm historically disadvantaged groups, meaning that even when achieving 100% accuracy on a dataset, a model's stability or learning is not foolproof. This has led to an increased emphasis on fairness and bias mitigation when developing and deploying AI systems.
Understanding Bias in AI
Bias in AI is when an AI system produces outcomes that systematically favor certain groups or individuals over others. The bias can stem from factors like biased training data, algorithmic processes, and even assumptions made during model development. Examples of biased AI systems have included facial recognition software struggling to identify individuals with darker skin tones, or voice recognition systems performing poorly with specific accents. In March 2023, the Federal Trade Commission's investigation into OpenAI following a complaint from the Center for Artificial Intelligence and Digital Policy highlighted the critical need for fair and unbiased AI systems.
The Impact of AI Biases on Various Spheres
AI's influence spans sectors like healthcare, finance, and transportation, but bias can undermine its potential benefits. In healthcare, AI aids in diagnosing illnesses and predicting treatment outcomes, but biased models might lead to inaccurate diagnoses for certain patient groups. In the finance sector, AI-driven determinations of creditworthiness and insurance premiums could unfairly penalize individuals due to biased training data. Autonomous vehicles, driven by AI, may struggle to navigate diverse pedestrian scenarios due to biased training data. These examples underline how AI biases can compromise effectiveness and fairness in various contexts.
- Healthcare: AI revolutionizes patient care, diagnosing diseases, and predicting outcomes. Yet, unfair AI can harm specific groups based on gender, and ethnicity. If trained on limited skin tones, it might misdiagnose women or diverse skin tones. A clear example would be a medical chatbot, if biased, could unintentionally reinforce gender stereotypes by associating caring qualities with nurses.
- Finance: AI assesses creditworthiness, insurance, and fraud. Training on low socioeconomic zip codes might unjustly penalize creditworthy individuals from these areas.
- Transportation: Autonomous vehicles promise safer roads. However, bias against certain pedestrian groups could hinder their effectiveness.
Click here to Push Ethical Boundaries with Heartfelt Automation in AI
Bias Across ML Lifecycle:
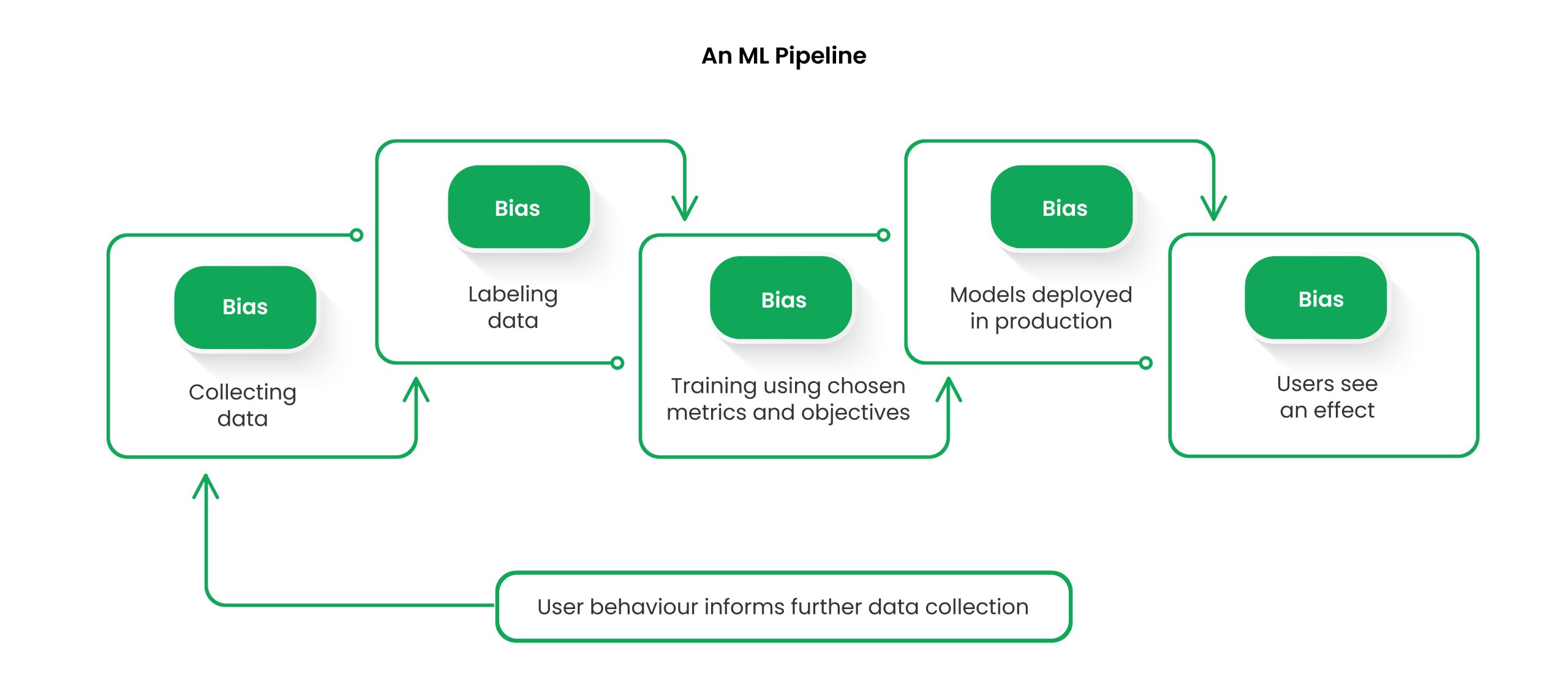
Bias can seep in at any ML stage:
- Data Collection: If data isn't representative, bias can creep in. Over- or under-representing certain groups leads to skewed models.
- Data Pre-processing: Cleaning and labeling data invites bias. Imputing gaps based on defaults like gender can introduce unfairness. Labeling toxicity in comments should also consider bias.
- Model Training: Biases arise if models aren't designed for fairness. Prioritizing accuracy without considering fairness leads to skewed outcomes. Training on biased data makes biases endure.
- Deployment: Model deployment brings new environment challenges. Different data in production vs. training can create unanticipated bias.
- Human Interpretation: Human evaluation can unknowingly introduce bias. Personal views may taint data understanding.
To counter bias, awareness, and action are key. Use diverse data, curate training data carefully, assess models fairly, employ mitigation techniques, and monitor deployed models. A holistic approach ensures fair AI.
Sources of Bias in ML Systems
Machine learning models are powerful tools that learn from data, but they can inherit biases present in that data, leading to fairness concerns. These biases can arise from various factors like data sampling, labeling, and processing.
Familiarity with these sources of bias can aid in selecting data, formulating data collection and labeling protocols, model training, and model assessment to ensure fairness.
A significant source of bias is representation bias, where models trained on data that are not representative of the entire population can lead to poor performance for certain groups. To illustrate, a facial recognition system predominantly trained on lighter-skinned faces could exhibit deficiencies in recognizing individuals with darker skin tones.
Confirmation bias, which involves the inclination to favor information that aligns with existing beliefs, can impact the human assessment of AI applications. For instance, if a researcher exclusively gathers data corroborating their hypothesis and dismisses contradictory evidence, they might unwittingly succumb to confirmation bias.
Evaluation bias emerges when models are trained on a broader set of attributes but tested on limited attributes, ignoring the diversity of real-world scenarios. As an example, if we validate a voting prediction model solely based on a local election, it inadvertently becomes tailored to that particular area. Consequently, other regions with divergent voting patterns remain inadequately accounted for, even if they were included in the initial training data.
Historical bias, stemming from pre-existing societal biases, can perpetuate unfair outcomes. This bias, often labeled as cultural bias, can reinforce negative stereotypes, making it crucial to address these issues.
The complexity deepens with the presence of proxies or correlated features. Even when sensitive attributes such as gender or race are eliminated, other factors can operate as proxies for these attributes, leading to unintended bias. These sources of bias emphasize the need to ensure fairness in machine learning systems.
Measuring Fairness in ML Models
Measuring fairness in AI models is a complex endeavor with varying approaches. Methods such as disparate impact analysis, equal opportunity, and counterfactual fairness provide ways to assess fairness. However, no single method provides a comprehensive measure. Instead, a combination of methods tailored to the specific context is essential for an accurate fairness assessment. Keep an eye out for our upcoming blog on “Fairness Metrics” to delve into these fairness metrics and how they facilitate evaluating models for fairness.
Addressing Bias in AI: Actionable Steps
To address biases, AI developers can take several approaches:
- Collecting and Using Diverse Data: Ensuring that training data represents a wide spectrum of individuals and groups.
- Data and Model Auditing: Analyzing training data and model performance to identify and rectify biases.
- Fairness Metrics: Using specialized metrics beyond accuracy to evaluate model fairness.
- Human Oversight: Incorporating human judgment to correct biases and maintain ethical outcomes.
- Algorithmic Transparency: Making AI algorithms understandable and transparent for bias identification.
- Diverse Development Teams: Building teams with diverse backgrounds to create unbiased AI systems.
- Continuous Measurement: Regularly assessing and adjusting AI systems to account for evolving biases.
Achieving Fairness in AI with Bias Mitigation Algorithms
Addressing fairness in AI involves various strategies, each with pros and cons. Removing sensitive attributes might not eliminate latent biases. For instance, race can still be inferred from names.
Bias mitigation algorithms provide ways to counter such biases which can be categorized into pre-processing, in-processing, and post-processing, tailored to different pipeline stages. Selection depends on the user's intervention capability: pre-processing if data modification is permitted, in-processing if algorithm change is allowed, and post-processing if the user can't alter data or algorithm.
- Pre-processing: Reweighing adjusts sample weights, ideal for applications with no value changes. Disparate impact remover, optimized pre-processing modify datasets in the same space. LFR’s pre-processed dataset is in a latent space, offering transparency.
- In-processing: Prejudice remover suits models with regularization terms. Adversarial de-biasing trains models and their adversaries for broader learning algorithms.
- Post-processing: Threshold tuning adjusts decision thresholds, while label swapping changes output labels based on probabilities.
Each method has strengths and weaknesses. The right choice depends on the context. A combination of these methods may be needed to effectively reduce bias.
Challenges in Addressing Bias and Fairness in AI Models
Fairness in AI models faces multifaceted challenges, from balancing trade-offs to addressing biases and lack of diversity. Striving for fairness requires overcoming these obstacles.
- Fairness-Accuracy Trade-off: Balancing fairness with goals like profits, user experience, and accuracy poses challenges. Enhancing fairness may decrease accuracy, affecting service quality or profits. Striking a compromise between fairness and accuracy is complex.
- Compromising Individual Fairness: Ensuring group fairness might harm individual fairness. For instance, a hiring model rejecting an applicant for overall fairness could lead to individual unfairness. Balancing both is intricate.
- Data Bias: Biased training data results in biased AI outcomes. Addressing data bias is a significant hurdle in achieving fairness.
- Lack of Diversity: Inclusive AI models require diverse teams. A lack of diversity in AI teams makes incorporating fairness challenging.
- Complex Fairness Definitions: Different fairness types—demographic parity, equal opportunity, individual fairness—create complexity in selecting the right definition for fairness.
- Limited Interpretability: Complex AI models lack transparency in decision-making. Interpreting them to ensure fairness is challenging.
Paving the Way for Fair AI
Addressing biases in AI is a shared responsibility. Transparency, inclusivity, diversity, and ethical considerations are pivotal. It's not just about eliminating biases; it's about fostering a culture of fairness. As we move forward, a collaborative effort encompassing developers, researchers, policymakers, and society at large is essential to ensure AI serves everyone, leaving no one behind.







