This blog post is a noteworthy contribution to the QuriousWriter Blog Contest.
Training new datasets involves complex workflows that include data validation, preprocessing, analysis and deployment. Building a Machine Learning (ML) pipeline enables automation of these workflows, reducing the time spent in training and reproducing models. Hence, it is important to architect an end-to-end scalable ML pipeline.
This post covers how to horizontally scale the process of creating tfrecords for a computer vision dataset and similar steps that can be followed for all semi-structured machine learning (ML) datasets. If you are familiar with creating tfrecords, you can directly find the code on the Github repository by clicking here.
A Brief Introduction to Tools
Dataflow is an ETL (Extract Transform and Load) tool on GCP (IaaS) which is used for data pre-processing and conversion. It is a pipeline service for processing streaming and batch data that implements workflows. In our case we use it to load images from a bucket, augment and save them to tfrecord in GCS Bucket.
Apache Beam is a framework for pipeline tasks. Dataflow is optimized for beam pipeline so we need to wrap our whole task of ETL into a beam pipeline. Apache Beam has some of its own defined transforms called composite transforms which can be used, but it also provides flexibility to make your own (user-defined) transforms and use that in the pipeline. Each user-defined transform should be designed for a specific task.
To learn the basic concepts for creating data pipelines in Python using the Apache Beam SDK, refer to this tutorial.
Planning Your Pipeline
In order to create tfrecords, we need to load each data sample, preprocess it, and make a tf-example such that it can be directly fed to an ML model. With the traditional approach using tf.python_io.TFRecordWriter() we need to iterate over each sample in the entire dataset to convert to tf-example and then later write it to tf-record. For huge datasets, it consumes a lot of time and also each small task (such as reading data from memory, performing preprocessing operations, creating tf-example, serializing example, writing serialized example, etc.) in your code won’t take an equal amount of time. So in this case a better way to optimize your code is to scale your entire task over various machines (i.e., scale horizontally). But even this is not optimal aseach small task in your code won’t take an equal amount of time. So the best way is to horizontally scale each small task in your code to number to machines depending on how much time those tasks need to execute (i.e., More machines assigned to reading the data than to serialize the example).
Fortunately, using Apache Beam and Google Dataflow we can achieve this quite easily. Break down your whole task of loading images and finally saving them into tfrecords into a number of smaller tasks where each subtask must be such that you are performing operations on a single sample (in our case, sample is an image). Let’s understand this with the example for Image Classification Dataset. The subtasks for this example will be:
Extract:
- Read Text line from CSV
- Decode the text line string into path and label
- Load image from the decode Google cloud storage path
Transform:
- Convert image and label into tf-example such that it can be directly fed to the ML model
- Serialize the tf-example to string
Load:
- Write the serialized example to tf-record
As you can see these are all the basic steps required to create the tfrecords. Now we will write the code for each subtask individually. For the complete code, you may visit this GitHub repo.
Extract
You may have metadata for your actual data stores in a text file or BigQuery table. Then during extraction, you can read from CSV, big query, or bucket.list_blobs() in GCS.
Make sure that the first block which you use in the pipeline is a beam function and not your custom function, since custom DoFn's (will be explained later) don’t support windowing which is used to enable horizontal scaling.
Below is a Python code example to create the first block in your pipeline:
The above function yields the text lines in your CSV or text file one at a time. You have to decode this text line (or it might be a row from the BigQuery table) using a custom function to extract the metadata required to read your actual data from the storage (in case of NLP problems you may directly have your actual data in text or CSV format).
Defining Custom DoFn's in python:
A custom DoFn has the following format:
Here, the process() function receives the yielded output value from the prior block as the input argument value. We can then extract the required information from this input argument, process it, and obtain the output_values which are required to be yielded for the next block in the pipeline. Using the above method you can define your custom DoFn’s to decode the text line and load the data into VM Instance memory. (refer GitHub code here)[Refer DecodeFromTextLineDoFn() and LoadImageDoFn()]
Transform
Once the data is being loaded you may create the tf-example using the following the DoFn example:
To serialize the example yielded from this DoFn you can write a lambda function directly in the pipeline as (refer defining pipeline for better understanding),
beam.Map(lambda x: x.SerializeToString())Load
To write the serialized examples as tfrecords on a bucket, use the beam’s own tfrecord record writer. This tfrecord writer writes the tfrecords on the output path provided as an argument. The number of tfrecords that are to be written can be controlled using num_shards. Below is an example:
# Write serialized example to tfrecords
write_to_tf_record = beam.io.tfrecordio.WriteToTFRecord(
file_path_prefix=OUTPUT_PATH,
num_shards=20)Defining the Pipeline
Pipeline Options
These arguments/options are needed to be provided in order to run the pipeline on Dataflow.
Here all are required arguments except for --template-location. The runner must be specified as DataflowRunner in order to run your pipeline on Google DataFlow, also DirectRunner can be specified for debugging purposes (this will make your entire pipeline run on a single VM).
setup.py is required as a package is needed to be created in order to run code on Dataflow. In the setup file we define the required packages for the module.
If you want to deploy/stage your pipeline and run it in a variety of environments you may deploy it as a template and reuse it as much as you desire. The --template_location is an optional argument that is to be provided only if you want to deploy the dataflow template on the bucket. To read more on templates you may follow the official documentation.
Defining Pipeline
All the pipeline blocks which you have defined before need to be wrapped in the following way to run the beam pipeline:
You may have noticed that the custom DoFn’s are written as beam.ParDo(custom_do_fn).
Running the Pipeline
In order to run the pipeline, you have to simply run the python code. The refer to the directory structure required to python package refer (github code).
Once you run the pipeline you will be able to see the following graph on Google Dataflow UI:
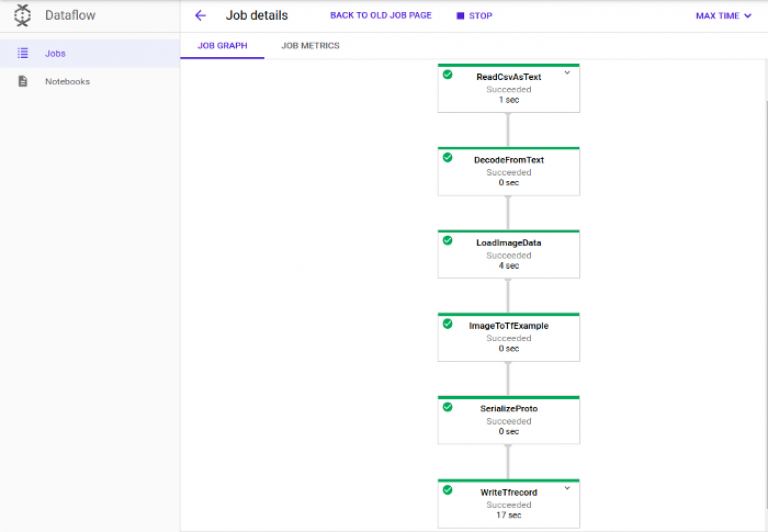
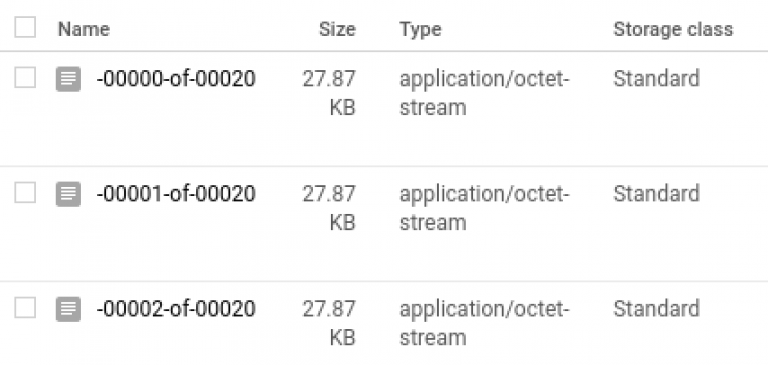
The pipeline may take 4–5 minutes to run and tfrecords will be created at the GCS output path provided as shown below:
Hope you were able to follow these steps. For any questions, post them in Github issues.